







我们和ChatGPT聊了聊BI的未来
ChatGPT是什么?
ChatGPT是OpenAI开发的聊天机器人,2022年11月上线,迅速火爆全球,1周突破100万用户,仅用2个月全球突破1亿用户,碾压史上所有应用程序。美国有学生用ChatGPT写论文拿下全班最高分,ChatGPT可以编程,通过了谷歌L3工程师的入职测试,年薪达18.3万美刀。
我们在第一时间注册了账号,准备和ChatGPT聊聊对BI行业发展的看法。我们发现ChatGPT已经达到垂直领域产品经理的水平,它不但对BI行业的发展有深刻的理解,同时自信地认为结合AI的数据智能分析助手会是BI的下一个形态,企业基于数据驱动的决策效率将得到大幅提高。
和ChatGPT聊聊BI的未来
第一个问题
【BI行业未来5年的发展情况如何】,它回答的观点与主流市场研究机构给出的方向基本一致:

第二个问题
【ChatGPT的出现会给BI行业发展带来哪些影响】,这个问题的回答体现出它的“思考”。它首先说明自己是基于NLP自然语言处理技术的AI系统,然后围绕自然语言处理技术与BI的结合展开观点,它的回答如下:

第三个问题
我们进一步深入提问:【ChatGPT能否使用企业内部数据进行训练,帮助企业提高数据获取与分析的效率,从而实现数据驱动】。它的回答是肯定,并表示结合企业的内部数据,可以训练出一个智能数据分析助手,实现数据驱动,主要通过:
1)与用户实现基于自然语言的对话式交互,进行数据查询、分析,提升;
2)帮用户进行数据分析与预测,快速从数据中获取关键信息。
我们认为,目前ChatGPT实际上还是基于互联网的公开数据进行训练,但使用企业内部数据训练出智能数据分析助手的想法非常具有前瞻性。

第四个问题
【这样做有什么安全隐患么】,这也是大部分企业都关心的实际问题:
它站在企业与自身的两个角度,给出了很客观的评价——“存在安全隐患”。并列举了,诸如:企业数据泄露、恶意数据污染训练集、模型训练选择性偏差等问题。
ChatGPT目前是在OpenAI内部的模型,目前训练消耗资源巨大,还无法做到多租户,更无法做到本地部署。

第五个问题
【中国有哪些对话式数据分析系统】,在这里我们看到了元年推出的产品“元年C1智答”,不由感叹ChatGPT果然识货:
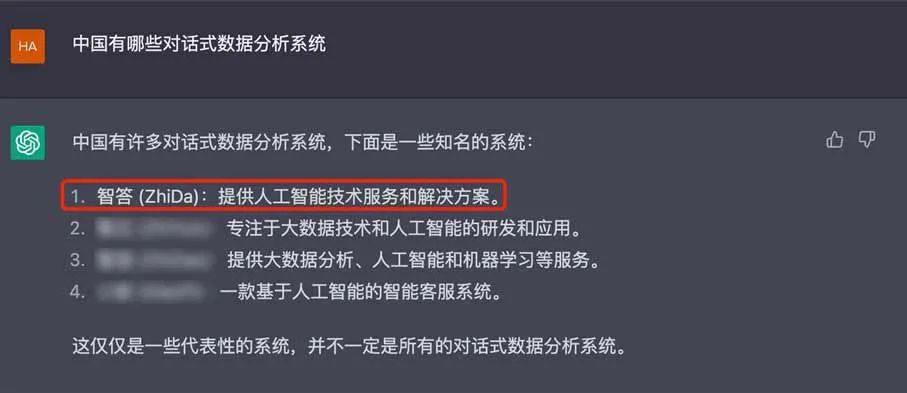
第六个问题
上一个问题信息量太少,我们尝试用ChatGPT【介绍下智答】,没想到它的答案基本涵盖了智答产品能力的关键点,也给出了总结:
智答是基于自然语言处理和人工智能技术的数据智能分析助手,帮助用户轻松进行数据查询、洞察分析、异常预警和可视化呈现。

ChatGPT是如何进行"思考"的
在惊叹于ChatGPT自信流畅的回答时,很多读者不禁想知道ChatGPT为何拥有"思考"的能力。在谈到AI的能力时,绕不开数据、算法、算力,我们从这三个方面简要介绍下ChatGPT是如何思考的。
数据部分
在有3000亿单词的语料上预训练拥有1750亿参数的模型(训练语料的60%来自于 2016 - 2019 的 C4 + 22% 来自于 WebText2 + 16% 来自于Books + 3%来自于Wikipedia)。
算法部分
先科普下GPT,它是Generative Pre-trained Transformer的缩写。
Generative是生成式的意思;
Pre-trained表示为预训练,模型在进行使用前经过了一定程度的训练,有了一些基础能力;
Transformer比较抽象是使用自注意力机制的深度神经网络,基本结构是Encod&Decode解码器。Encode负责理解输入文本,为每个输入构造对应的语义表示(语义特征),Decode负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。自注意力机制用于捕获句子中窗口期内的关系。更多地关注句子中的某些词语,而在一定程度上忽略其他词语,也就是将注意力只放在某些词语上。
ChatGPT的是基于大规模预训练语言模型(GPT-3.5),借助其强大的语言理解和生成能力,通过在人工标注和反馈的大规模数据上进行学习,从而让预训练语言模型能够更好地理解人类的问题并给出更好的回复。通过引入人工标注和反馈,解决了自然语言生成结果不易评价的问题,最后利用强化学习技术,通过尝试生成不同的结果并对结果进行评分,然后鼓励评分高的策略、惩罚评分低的策略,最终获得更好的模型。通过ChatGPT我们看到RLHF的强大(Reinforcement Learning from Human Feedback 人类反馈的强化学习技术)。
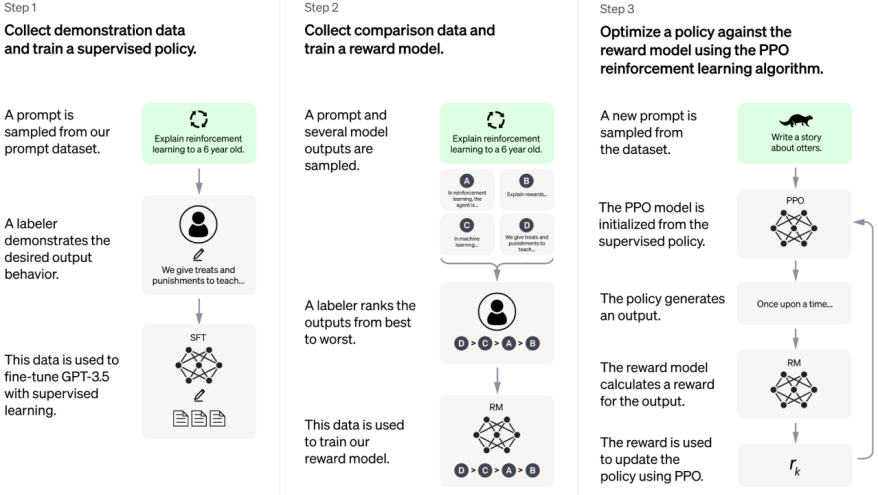
第一阶段,进行有监督的训练,针对一些问题写出人工答案,再把这些问题和答案给 GPT 学习。这时并不需要列举出所有可能的问题和答案,GPT 有能力产生正确答案,只是不知道哪些是人类所需的。
第二阶段,给GPT请一个老师,通过让 GPT 对特定问题给出多个答案,由训练师对这些答案的好坏做排序。基于这些评价数据,训练出一个符合人类评价标准的 Reward 模型(老师模型)。
第三阶段,用AI训练AI,进行强化学习不断优化模型。随机向 ChatGPT 提问,让 Reward 模型(老师模型)给这个回答一个评分,ChatGPT基于评分去调整参数,以便在下次回答中获得更高分。不断重复这个过程,使模型产生更加符合人类偏好的回复。
算力部分
由于ChatGPT的训练语料过于庞大,需要强大算力来支持,目前OpenAI未发布确切的算力数据。据国盛证券估计,维持迭代运行ChatGPT芯片需求为3万多片英伟达A100GPU,对应初始投入成本约为8亿美元,每日电费在5万美元左右。
面向中国企业的数据智能助手:元年C1智答
ChatGPT的背后是大数据、大模型、大算力,是AI的能力集中化的典型场景。ChatGPT不支持进行私有化,企业无法承担ChatGPT的私有化的成本,如要用ChatGPT训练需要需将自身商业机密数据提供给OpenAI。
那么国内的企业如何在数智化的浪潮中,利用AI技术加速数据驱动的进程呢?可以试试面向中国企业的数据智能助手“智答”。
元年C1智答支持基础数据查询、数据实时筛选&运算、数据归因分析、模糊意图分析、数据预测、数据洞察等,并根据数据特征,自动推荐适合图表,使用者可随时随地、实时高效的对数据进行“无门槛”的交互。目前,我们已经给智答扩展了GPT3.0的模型。















